Get 40 Hours Free Developer Trial
Test Our Developers for 40 Hours at No Cost - Start Your Free Trial →

Data Cleaning and Transformation: Tips for Accurate Data Management
Data cleaning and transformation are important processes for your business, especially considering that poor-quality data costs the United States economy a staggering $3.1 trillion every year. In fact, companies believe that 32% of their data is inaccurate. Whereas raw data is naturally complex and confusing, well-crafted data reveals patterns, trends, and values that would otherwise […]
![]()
26 Aug, 2025
Data Cleaning and Transformation: Tips for Accurate Data Management
Data cleaning and transformation are important processes for your business, especially considering that poor-quality data costs the United States economy a staggering $3.1 trillion every year. In fact, companies believe that 32% of their data is inaccurate. Whereas raw data is naturally complex and confusing, well-crafted data reveals patterns, trends, and values that would otherwise remain hidden.
Before starting data analysis, you need to learn about the steps that process raw data and make it accessible to gain insights from. Two different, though complementary processes that drive proper data management: data cleaning and data transformation.
What is Data Cleaning?
Data cleaning (sometimes called data cleansing) is the process of finding and correcting errors, inconsistencies, and wrong information in datasets. This first & important step improves data quality by eliminating issues that might cause incorrect analysis.
The primary purpose of data cleaning is to ensure your data remains accurate, reliable, and consistent for better decision-making. Cleaning data involves various key aspects related to the quality of the data.
- Accuracy shows how the data matches the actual attribute it represents.
- Completeness measures how much data is missing in a dataset.
- Consistency checks if data stays uniform across different systems or sources.
- Integrity refers to whether the relationships between different data elements are valid.
- Uniqueness ensures there are no duplicates or repeated data.
- Validity examines the percentage of data that follows the required syntax.
What is Data Transformation?
Data transformation is the conversion of data from one format into another format or structure. Unlike cleaning, it transforms how you store and present your data, enabling you to use it for other purposes.
Data transformation is the processing step for either the ETL (Extract, Transform, and Load) or the ELT (Extract, Load, and Transform) method. Three main stages are involved in both procedures:
- Extraction involves gathering needed data from different sources.
- Transformation rearranges or reshapes this collected data into a preferred format.
- Loading sends the updated data into a database to process it or run analyses.
This process also aids in normalizing datasets to remove redundancies, which helps make the data model clearer and easier to understand. It also cuts down on storage needs.
Importance of Data Cleaning and Transformation
Data cleaning and data transformation play different but interconnected roles in getting data ready to use. Cleaning comes first, fixing errors to set up a solid base. After that, transforming reshapes the clean data into forms that work better for interpreting, reporting, or analyzing.
Improved data quality
Cleaning and transforming data, organizing, verifying, and formatting it the right way. This process prevents problems like null values, duplicate entries, or mismatched formats from causing trouble in applications.
Enhance Accessibility
When processed, data becomes more accessible to both systems and users. It improves how different software, platforms, and data formats work together.
Better Decision Making
Refined and well organized data helps businesses rely on intelligence and allows analysts, scientists, and business teams to make smarter choices.

Operational efficiency
Removes barriers between different data systems, bringing together information from various areas of your business. This clears up mismatched data and gives a complete picture of operations.
Data cleansing and data transformation do more than just handle tech tasks. They are essential steps that affect your business’s ability to make smart choices, maintain compliance, boost efficiency, and stay ahead in the competition.
Key Techniques for Data Cleaning
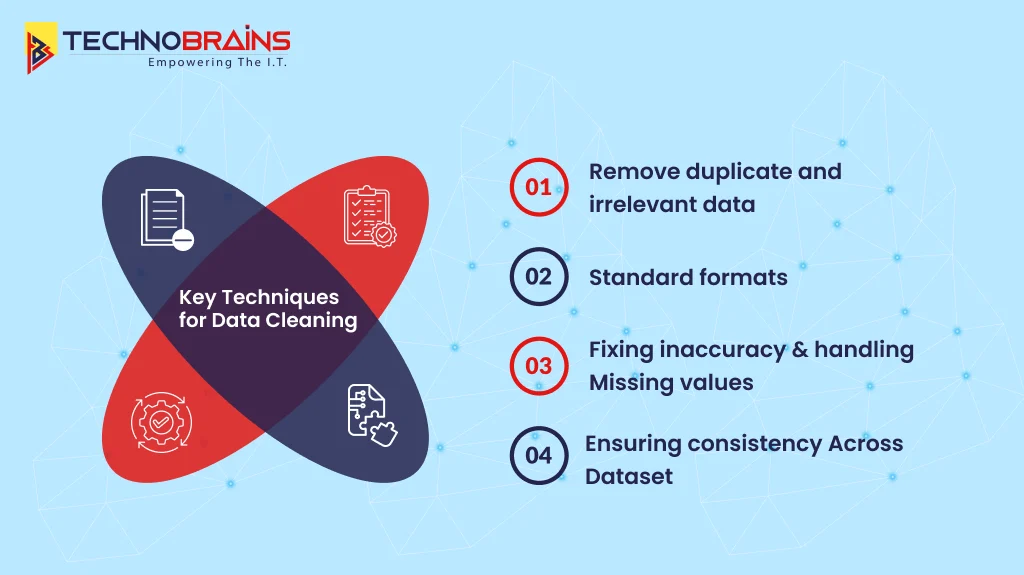
For effective data cleaning, you need specific techniques to identify and address issues in data quality that could compromise your analytics. Instead of using one general method, you need several different approaches that work together to solve specific types of data problems.
Remove duplicate and irrelevant data
Duplicate entries can disrupt your analysis by adding extra data points and skewing your results. These repeats often appear when integrating data from multiple sources into a single location. To tackle this, you should use strong methods to handle deduplication.
Start by finding duplicate rows by comparing them using specific rules. Many data management tools come with features to match records and remove duplicates. After identifying them, you can:
- Keep one version of each duplicate and delete the rest
- Combine repeated records to make more complete ones
- Use set rules to save the most accurate version of the data
Duplicates and irrelevant data add clutter to your dataset by including information that isn’t useful to your goals. Cleaning out this excess makes it easier to work with and keeps your dataset more targeted. For example, when analyzing millennial customer trends, any data tied to other age groups might not be needed and can be removed to simplify your analysis.
Standard formats
Inconsistent formats make analyzing and combining data harder. Standardizing data changes the raw information into a single format that maintains uniformity throughout the dataset. This step matters because different sources often present the same details in different formats.
Making some elements (name, phone numbers, dates, states, job titles, etc) uniform removes repetition and errors, which improves data quality as a whole. Setting up data validation rules when information is first entered is one of the best methods to keep data consistent over its entire lifespan.
Fixing inaccuracy and handling missing values
Organizations lose approx. $12.9 million each year because of bad data. Errors like typos, wrong entries, or problems during measurement and transfer cause this loss.
To fix these problems:
- Use automated tools to enter data and avoid human mistakes.
- Set up systems that check and flag bad data.
- Match incorrect data with reliable sources to fix errors.
Incomplete data can make things difficult since many algorithms struggle with datasets that have gaps. There are a few ways to deal with this issue:
- Remove rows with null values, which works well if the gaps are random.
- Fill the missing values using simple stats like mean, median, or mode.
- Apply more complex methods, like multiple imputation, to address larger gaps.
Every method has its pros and cons. So, the right choice depends on how much data is missing and whether the pattern is random or follows a trend.
Ensuring consistency across dataset
Maintaining data consistency involves ensuring that your datasets and systems align. Errors during entry, problems in software, or systems using different formats often lead to mismatched data.
Simple ways to make your data more consistent:
- Define clear rules for structuring, formatting, and naming your data and stick to them.
- Eliminate isolated data by establishing a single, reliable source for everyone.
- Check your data to confirm it follows the rules you set.
- Build a layer to define important metrics that people in your organization can use.
Inconsistent data occurs because there are no clear rules in place to manage information. Setting up standard processes helps your organization keep data quality at a good level. Running routine data checks also helps spot issues so you can keep your data accurate and steady in the long run.
If you are interested in data backup and recovery, you might also like to read: Comprehensive Guide to Backup and Disaster Recovery.
Data Transformation Methods
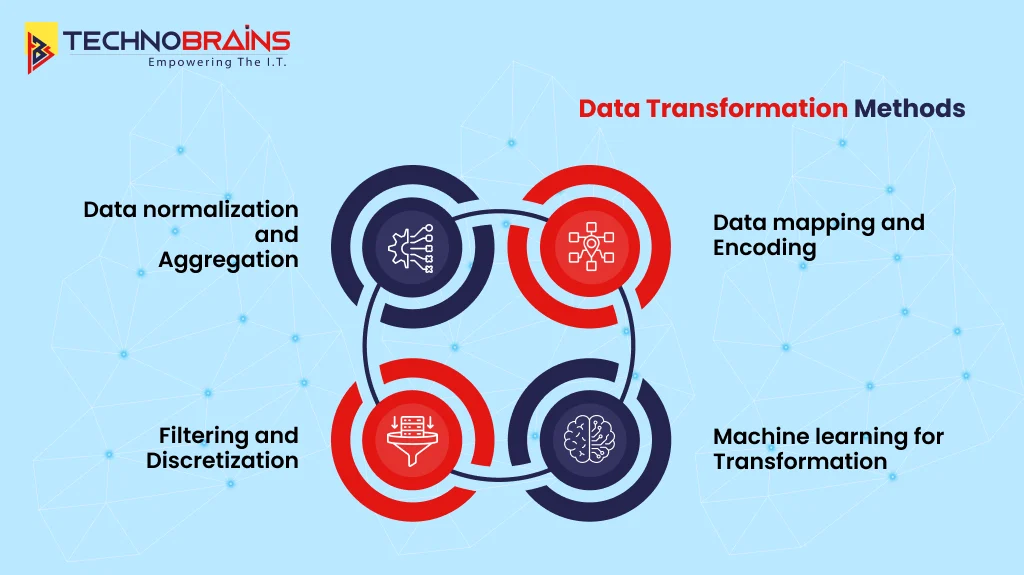
After cleaning your data, the next important task is to turn it into a usable format. Here are some handy data transformation methods to change raw data into something that makes sense and provides a helpful understanding.
Data normalization and aggregation
Normalization adjusts features to the same scale to help models train faster, make predictions more accurate, and avoid issues like “NaN errors” from exceeding precision limits. Popular methods include Linear scaling, Z-score scaling, and log scaling.
Aggregation compiles multiple data entries into summarized forms. It collects raw data from various sources and converts it into a consistent format. Time aggregation organizes data into fixed intervals, such as hourly or daily, and spatial aggregation groups data from multiple sources over a chosen time span.
Data mapping and encoding
Data mapping connects fields from one database to a second database. This forms the starting point for moving and merging information between systems. It helps resolve differences between the two setups or models, ensuring data remains accurate and useful when transferred from one place to another.
Encoding changes categories into numbers to process data more. Methods include:
- One-hot encoding creates separate binary columns for each category.
- Label encoding turns each category into a unique number.
- Ordinal encoding assigns numbers based on an order or rank.
Filtering and discretization
Filtering keeps the data that fits certain conditions, which helps shrink the dataset. Discretization changes continuous data into chunks or intervals, which makes it easier to analyze. Equal-width discretization splits continuous numbers into intervals of the same size. Equal-frequency discretization arranges the data into intervals with an equal number of entries in each.
Machine learning for transformation
Machine learning models now act as smart tools to transform data in advanced ways. They find the best transformations on their own by using methods such as:
- Feature engineering involves creating new attributes to capture hidden patterns better.
- Embedding creation, which helps create compact data representations to use in tasks like recommendations or search functions.
- Automated mapping applies clever algorithms to line up fields between different datasets.
These methods let ML models uncover tricky patterns in data that people would struggle to find. Large and complicated datasets especially benefit from these methods since they create quicker and more accurate results than traditional approaches.
Also read, Top Python Libraries for Data Science and Machine Learning.
Data Cleaning and Transformation Tools and Services
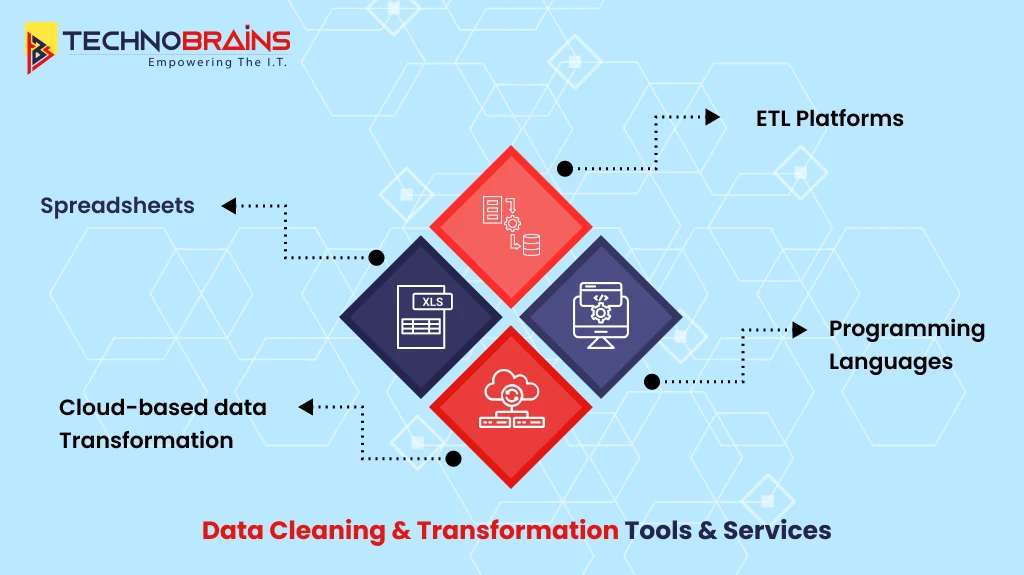
Choosing the right tools has a big effect on how you can clean and transform data. Many choices are available today to match different skills and project requirements.
Spreadsheets: Excel and Google Sheets
Microsoft Excel has many built-in tools to help clean data, even though people sometimes forget about them. On the Data tab, you can find an option to remove duplicates. Format Cells lets you make formatting consistent. Functions such as TRIM, CLEAN, and PROPER help tidy up messy text.
Google Sheets includes Smart Cleanup features that find typical mistakes. Cleanup Suggestions can help to fix things like extra spaces, uneven formatting, or odd errors in your data.
ETL Platforms (Talend, Informatica)
Talend Data Preparation provides users with a browser tool to quickly identify problems and apply repeatable rules. With its easy-to-use setup, users can profile, clean, and enrich data as it happens. It also lets users share their work and link it to many integration setups.
Informatica PowerCenter shines with its powerful integration features. The tools support tasks like ensuring data quality, managing governance, and handling both real-time and batch processes. Businesses needing detailed workflows for transforming data find it helpful.
Programming languages (Python, R)
Python makes data cleaning easier with its libraries. Pandas works well when managing missing data. Other tools include PyJanitor for cleaning column names, Feature-Engine for handling data imputation, and Cleanlab for tidying up machine learning dataset labels.
R has packages that handle data transformation. Using dlookr, users can detect data issues and fill in missing values by methods like mean, median or mode. It changes skewed data and displays visuals of the updated variables.
Cloud-based data transformation
Cloud platforms offer flexible options to transform data. AWS Glue allows users to find, prep, and change data without setting up their own infrastructure. Google Cloud Dataflow manages both live and batch data processing, while adjusting resources. Learn how TechnoBrains’ AWS Cloud services and Google Cloud services can help your business improve data management.
Common Challenges and How to Overcome Them
Every advanced data management software system faces hurdles that might disrupt analytics work. Knowing these problems allows you to create ways to handle them.
Dealing with mixed-up data formats
Inconsistent data formats show up when data comes in from different places. This hinders integration efforts and makes it tough to pull data together. Trying to squeeze all the info into one size fits all can lead to mistakes or losing important details.
Steps to fix this include:
- Use tools like ETL programs to handle format changes
- Set clear rules within the team on how common data types should look
- Use strong data management systems that can handle many formats
Avoid over-cleaning and data loss
Over-cleaning occurs when key data is removed or altered. To avoid this, make sure to back up the raw dataset before the cleaning starts. Having the original data lets you check the cleaned version against it so you don’t lose important details.
Handling large-scale data transformations
Companies collect vast amounts of data from various sources, making it harder to transform. This puts pressure on systems and can delay work. To tackle these problems, you can:
- Split big data into smaller, easier-to-handle chunks
- Use automated tools to handle tasks that repeat
- Rely on cloud services that adjust to your growing data needs
Post-transformation data accuracy
Run automated scripts to verify data stays accurate by matching row counts in the source and target datasets. Create hash values or checksums for the source data and compare these with hashes from the transformed data to spot any unexpected changes.
Conclusion
In conclusion, data cleaning and transformation help change messy or incorrect information into solid and useful insights. Cleaning gets rid of mistakes and repeated data to boost quality. Transformation reshapes information so analysis becomes easier. These steps together cut down waste and make decision-making better for your team.
To do it well, you need good tools, clear guidelines, and strong checks that keep the data reliable. A solid plan for handling data can lead to faster results, meeting rules, and smarter choices for your business.
At TechnoBrains, we help companies create data management systems that match their needs. Want to make your data work better for you? Reach out to us today to get started.
Data Cleaning and Transformation: FAQs
What is data cleaning, and why is it important?
Data cleaning removes mistakes, duplicates, or inconsistencies from data. It ensures accuracy, reliability, and consistency, which improves business decision-making.
What is data transformation in data management?
Data transformation is converting data into a new format or structure. It helps standardize, normalize, and prepare data for analysis, reporting, or storage.
What are the main techniques for data cleaning?
Some common data cleaning techniques are removing duplicates, handling missing values, standardizing formats, validating accuracy, and ensuring consistency across datasets.
What are the methods of data transformation?
Key methods include normalization, aggregation, data mapping, encoding, filtering, discretization, and machine learning-based feature engineering.
What tools are commonly used for cleaning and transforming data?
Popular tools include Excel, Google Sheets, Talend, Informatica, Python, R (dlookr), AWS Glue, and Google Cloud Dataflow.
What challenges comes in data cleaning and transformation?
Typical challenges include inconsistent formats, handling large-scale datasets, avoiding over-cleaning, and ensuring post-transformation accuracy.